Using Semantic Metadata for easier integration
- Date
 Marty Pitt
Marty Pitt
Building and maintaining integration between microservices (APIs, DBs, Queues, Serverless compute) takes lots of time consuming, low-value work:
- Locating the right Team, API and Operation that needs to be called
- Using an OpenAPI code-gen tool to generate client code
- Tracking down the inputs needed
- Doing any additional calls to resolve ids etc.
- Combining together multiple calls to fetch the data needed
This work gets repeated by each team who have an integration requirement, over and over. Work performed by one team provides very little that makes it more cost effective for the next team, so there’s no real network effect or compound benefit.
And, the result is really brittle. Each painstaking integration will inevitably break as things change, causing each team to go and repair their glue.
This is work that ideally, we would automate away. After all, we’re already using tools like OpenAPI / gRPC / graphQL which describe our services well - so why is this work still so manual?
Turns out, while OpenAPI and friends are helpful for describing a single API, they don’t go far enough to describe how systems relate with one another.
API Contracts describe structure, not meaning
API Contracts (OpenAPI / Protobuf / etc) are great, but focus exclusively on How to interact with them and read data. They don’t talk about What data you’ll find there.
What exactly is in the name field on that model? First Name? Last Name? Street Name? Product Name? There’s no way to know.
This is because API contracts describe structure and interaction, but not meaning.
Fundamentally, data across the wire is just a map of fields and values (or lists of maps). API contracts are great at telling us what field names to expect, but they don’t really do a good job of describing what information I’ll find there.
Field names are a bad proxy for Semantics
Field names give developers a hint as to what information they’ll find in each field. However, they’re pretty hit & miss, and they don’t form any sort of semantic contract. For example, if we have two fields called customerId -
are they the same information?
On the flipside, the same data attribute may be named different things - eg., customerId, and Acct_ID.
Standardizing on field names isn't the answer
It’s ok for field names to be non-standard - they’re designed by the team who owns the producing API, and providing they choose descriptive names that makes sense within the bounded context of their domain, that’s fine.
We’ve seen teams try to solve this confusion by enforcing standards or a single global model across the enterprise (“Enterprise Domain Models”, or “Common Domain Model”), and it never works out well.
Many teams waste countless cycles trying to implement this, and it almost never yields results. Teams embrace microservices so they can evolve independently. Requiring a single global domain model across the enterprise removes this ability.
In fact, it makes the situation much worse. When shared domain models evolve (as they inevitably will), changes have to be rolled out company wide, leading to nightmarish change control and high cost-of-change.
What's better? And why should we care?
If we were able to document how data between systems links together, we can enable a new form of tooling, which reduces the pain of building, testing & maintaining integration between data sources.
Once we understand how systems relate, we can automate the plumbing work. Tools like OpenAPI already tell us how to communicate and interact with systems — they’re just missing the semantic layer that tells us what we’ll get.
Documenting relationships with Semantic Metadata
Today, when developers build integration between systems, they form a mental model of how systems stitch together:
- We eyeball OpenAPI specs, and try to work out which field contains the data I need
- We eventually work out how My data, and your API are related.
- Code up some integration code (this takes a fair bit of time), and move on.
- We swiftly forget the mental model we just built, and leave nothing for the next person.
We’re just not very good at capturing that information. As a result, orgs do it over and over - and often inconsistently.
Wiring together API’s boils down to finding fields that have the same content - regardless what it’s called. Fields that are semantically equivalent. What’s missing in our API specs is a way to label that two pieces of information between systems are related. This is Semantic Metadata.
What is semantic metadata
- Metadata that defines a contract for a field’s content - independent of the name of the field.
- It’s cross-platform - defined outside of individual systems.
- Systems then use the metadata to tag elements of their APIs that provide specific bits of information
Lets take a look at an example:
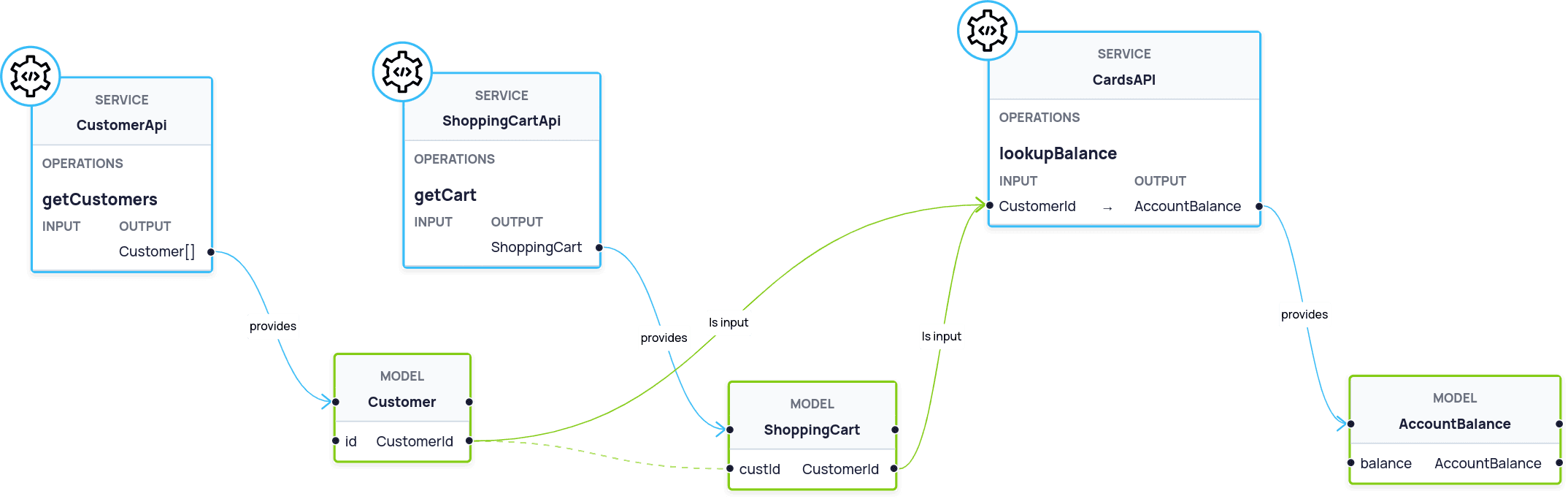
Imagine we have 3 systems:
- A ShoppingCart API
- A Customers API
- And an AccountBalance API, which takes a Customer number, and returns an Account Balance.

We’d like to capture the following:
- Both
Customer.idandShoppingCart.custIdcontain the same bit of information - aCustomerId - That
CustomerIdcan be passed toCardsApi.lookupBalance()to return anAccountBalance
Defining a semantic type
Taxi is an Open Source schema meta-language, used for describing APIs, data, and how they relate.
It’s different from OpenAPI etc, in that it focusses on describing the relationship between multiple systems. While you can use it as a full replacement for OpenAPI, it also has high interoperability, meaning you can use it alongside OpenAPI (and Protobuf / Avro / JSON Schema etc) to enrich existing specs. That’s how we’ll use it today.
Taxi lets us define a simple scalar type. This is a system agnostic idea - just a simple tag of a data element.
// Define a semantic type
type CustomerId inherits StringWe can then embed this type into our OpenAPI specs to indicate how fields relate:
# An extract of the ShoppingCartApi OpenAPI spec:
components:
schemas:
ShoppingCart:
properties:
custId: # Field name
x-taxi-type:
name: CustomerId # <-- Semantic type
type: string We now have a formal way of modelling that data can flow between systems:
Semantic, declarative integration
By combining OpenAPI (which tells us how to interact with systems) with Taxi (which lets us reference the returned data), we’re able to automate the integration between these systems.
Taxi provides a query language for asking for data, and Orbital is an integration platform that understands Taxi queries.
For example, we could run the following:
// Find customers and their account balances
find { Customer(CustomerId == '123') } as {
// In taxi, query consumers define their own response contract.
// This means that as schemas change, consumers remain unaffected.
// For example, here - we've defined field names
// that make sense to us, rather than what the producers used.
customerId : CustomerId
balance : AccountBalance
}Orbital would execute this query as follows:
This type of declarative, semantic integration is really very powerful. However, exploring this in detail is beyond the scope of this blog post.
Keeping things decoupled
Even though we now know how the data between the systems relates, we’ve kept everything loosely coupled.
Our services don’t explicitly know about each other - so they’re free to continue to evolve independently. In fact, making changes has become easier.
For example, we could rename the ShoppingCart.custId field to customerId, or even reshape the response, nesting the customer id.
Tooling that has been leveraging the semantic types for system integration remain unaffected:
# An extract of the ShoppingCartApi OpenAPI spec:
components:
schemas:
ShoppingCart:
properties:
custId: # Old Field name
customerId: # New Field name
x-taxi-type:
name: CustomerId # <-- Semantic type
type: string
Summary
Microservices have huge potential to allow teams to build, ship and iterate at pace. However, integration is a real bottleneck, because of the repetitive manual work required to keep everything working.
Semantic metadata is a key building block for allowing teams to describe how things relate, enabling powerful automation of integration, all while keeping teams and systems decoupled from one another.