Guides
Composing APIs and a Database
This guide focuses on stitching together APIs and a Database, to create a custom API for our needs. You’d typically use this in a Backend-for-frontend (BFF) pattern.
Get the source...
This demo takes place in a fictitious film studio. Our goal is to stitch together data about our Films catalog, along with data from REST APIs, like the reviews of each film, and where we can watch it.
Our demo services
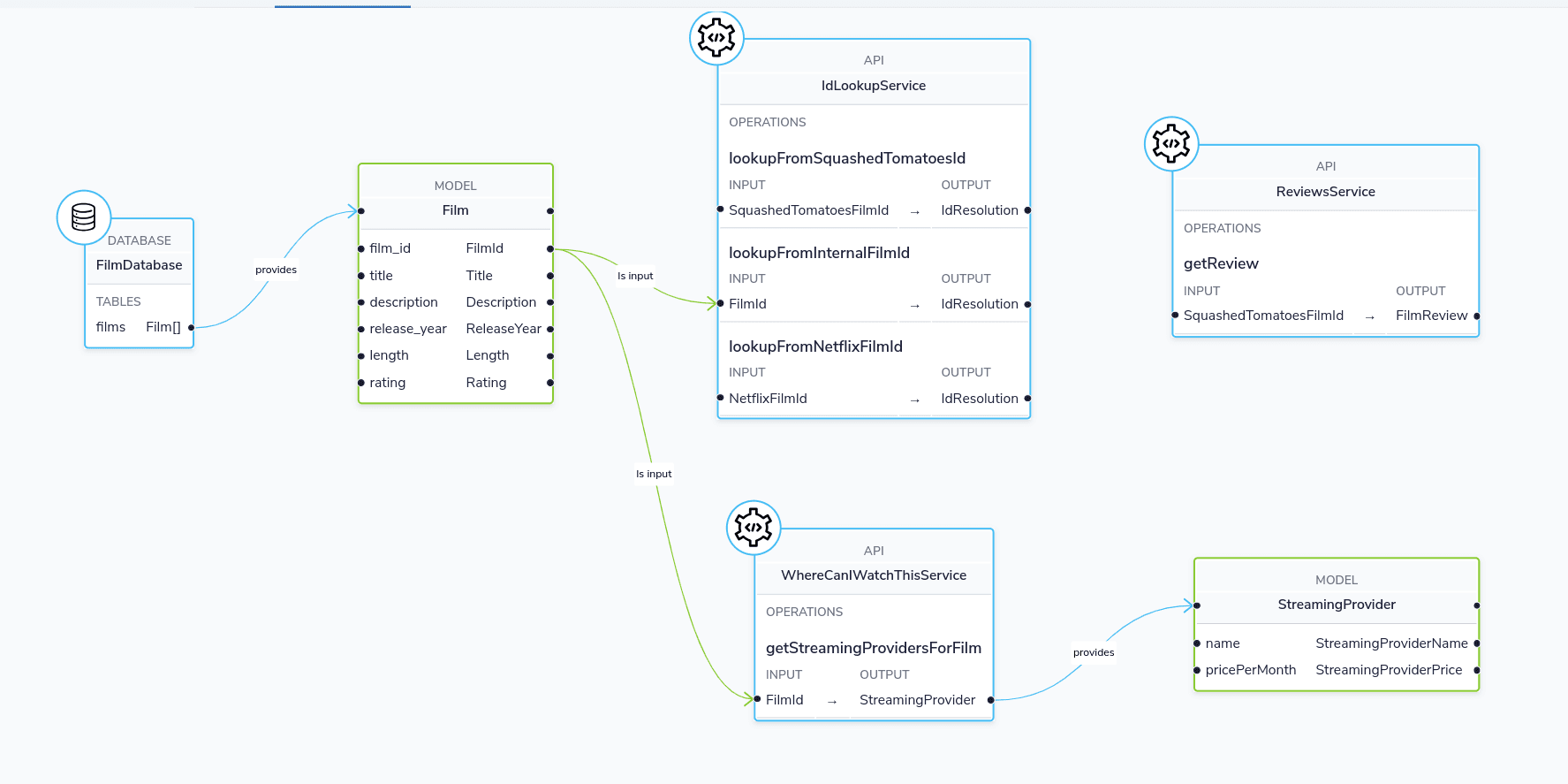
This demo deploys the following:
- A database exposing a catalog of Films
- A REST Endpoint that returns which streaming services are playing each film
- A REST Endpoint that returns reviews for each film
- A REST Endpoint that resolves ids.
- Our services have different ID schemes - specifically the IDs used in our DB are not the same IDs used by our FilmReviews API. Therefore, we need to map one set of Ids to another.
Describing our data and services
First, we’ll define a handful of Taxi types to describe the data returned from our services:
type StreamingProviderName inherits String
type StreamingProviderPrice inherits Decimal
type FilmId inherits Int
type Description inherits String
type Title inherits StringThen we’ll embed those types in our REST APIs.
We’ve shown this approach in a few different ways, depending on your preferred approach for describing APIs:
OpenAPI is pretty verbose. To keep things clear, we're just showing the relevant extracts here. The full OpenAPI spec is available on Github
paths:
/reviews/{filmId}:
get:
parameters:
- name: filmId
in: path
schema:
type: string
x-taxi-type:
name: films.reviews.SquashedTomatoesFilmId
/films/{filmId}/streamingProviders:
get:
parameters:
- name: filmId
in: path
schema:
type: integer
format: int32
x-taxi-type:
name: films.FilmId
components:
schemas:
StreamingProvider:
type: object
properties:
name:
type: string
x-taxi-type:
name: films.StreamingProviderName
pricePerMonth:
type: number
x-taxi-type:
name: films.StreamingProviderPrice
FilmReview:
type: object
properties:
filmId:
type: string
x-taxi-type:
name: films.reviews.SquashedTomatoesFilmId
score:
type: number
x-taxi-type:
name: films.reviews.FilmReviewScore
filmReview:
type: string
x-taxi-type:
name: films.reviews.ReviewText
Publish our API specs
Now that the API specs have taxi metadata, we can publish them to Orbital
file {
projects = [
{path: "taxi/taxi.conf"},
{
path: "services/api-docs.yaml",
loader: {
packageType: OpenApi
identifier: {
organisation: "com.petflix"
name: "PetflixServices"
version: "0.1.20"
},
defaultNamespace: "com.petflix"
}
}
]
}
Composing APIs
Our APIs are now described and published to Orbital, so we can start writing queries to ask for data.
In the Query Editor, write a query to ask for data coming from the 3 APIs.
find { Film[] } as {
id : FilmId
title : Title
review: FilmReviewScore
reviewText: ReviewText
availableOn: StreamingProviderName
price: StreamingProviderPrice
}[]Notice that as you’re typing, you get nice code completion.
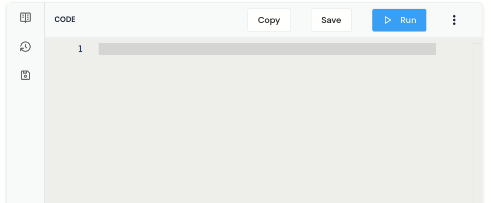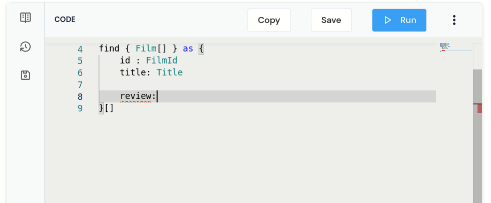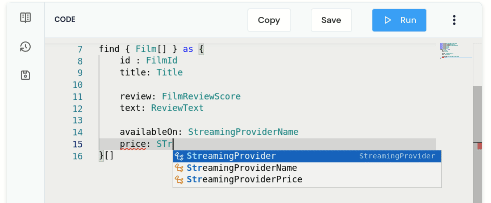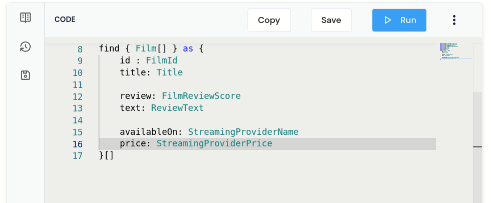
Run this query, and you’ll get the results back, linking together data from our Database, and 3 different REST APIs.
Exploring the profiler
Click on the Profiler tab, and you’ll see an architecture diagram, showing all the services that were called for each field:
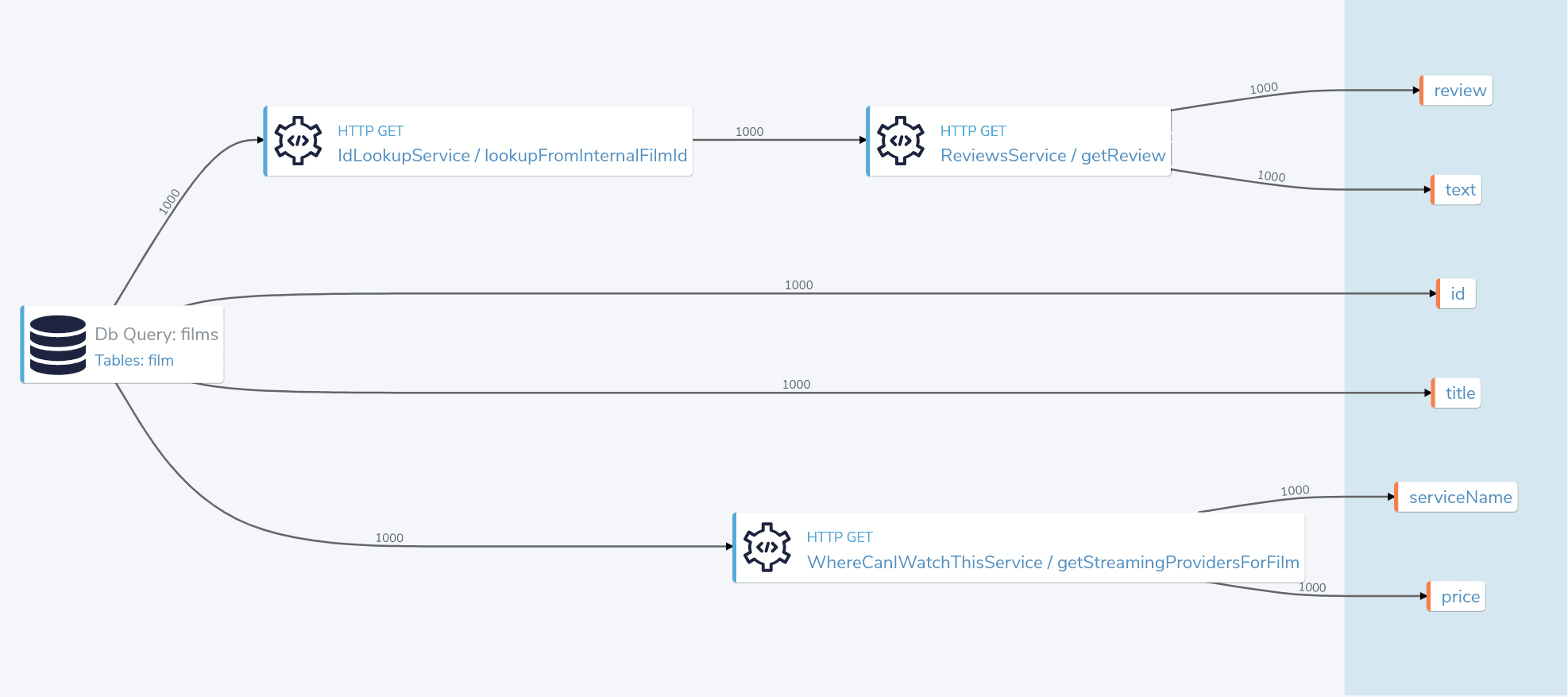
Note that
- To fetch our
serviceNameandprice, we passed data from the Db to a REST API - To fetch the review data, we had to take a trip to an additional API to resolve the Ids
How does this work?
There’s no resolver or glue code written here, so how does this all work?
Orbital uses the types in our query (FilmReviewScore, ReviewText, etc), and looks up
the services that expose these values, then builds an integration plan to load the required
data.
Exposing a composite API
Now we have the data we want to expose, we can publish this on an API.
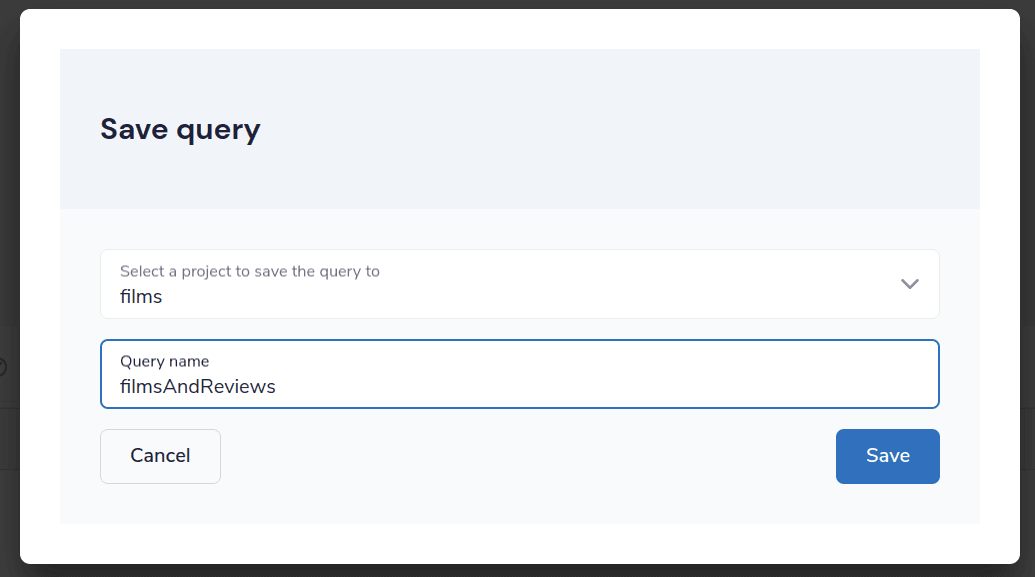
- First click “Save”
- In the popup, for the project, select “films”
- For the query name, enter
filmsAndReviews(or any name you choose) - Click Save
If you take a look in the source code, a new file has appeared at taxi/src/filmsAndReviews.taxi.
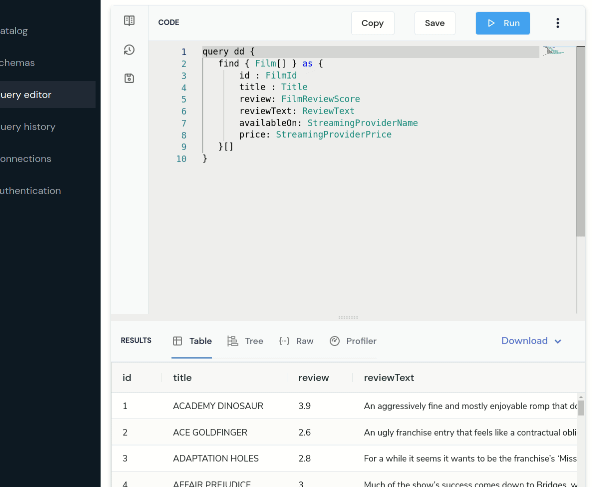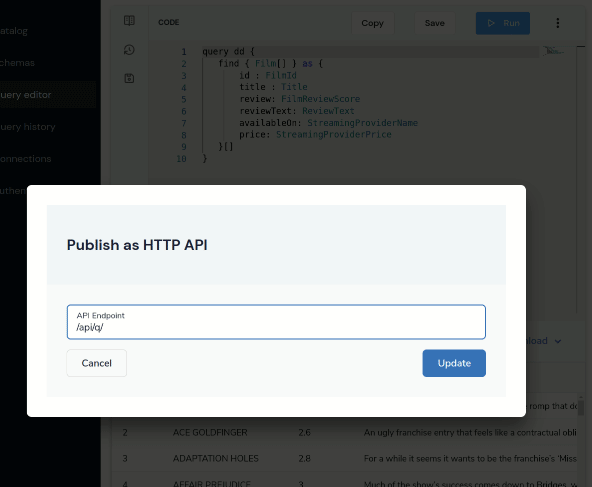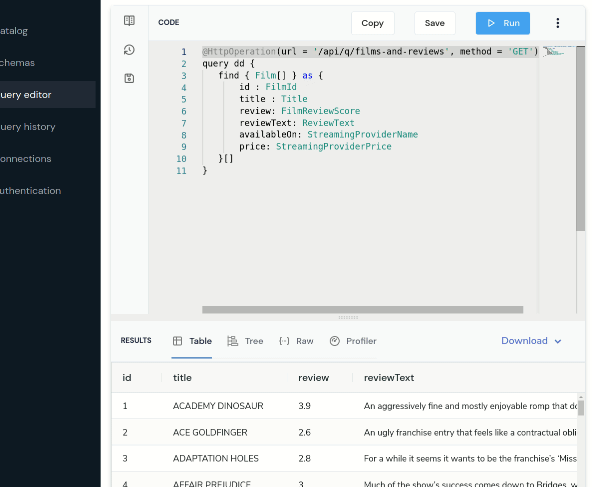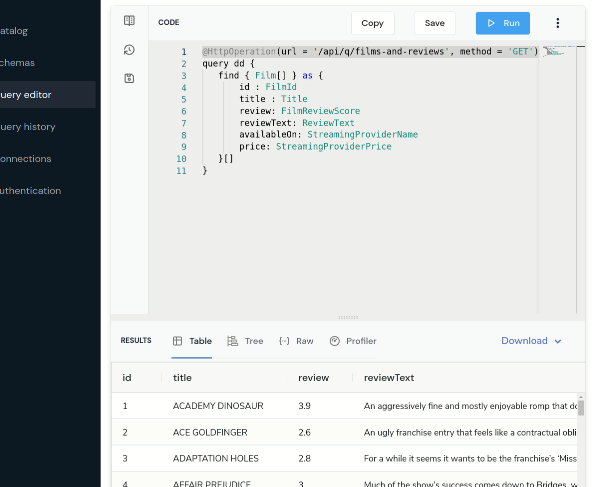
Next, let’s expose this saved query as an HTTP endpoint.
- In the top menu, click the 3-dots menu item
- Click Publish query as HTTP Endpoint
- In the popup, enter a URL for the query - eg:
films-and-reviews - Click Update
- Click Save
Now, send a request to the endpoint you selected. (As we’re getting JSON back, we’ll pipe it to jq so it’s nicely formatted)
curl http://localhost:9022/api/q/films-and-reviews | jq {
"id": 904,
"title": "TRAIN BUNCH",
"review": 4.6,
"reviewText": "This is not one of those awful dark, depressing films about an impending genetic apocalypse, although it could have easily been turned into that with a few minor tweaks. This is an entertaining romp, loaded with action, nostalgia and special effects.",
"availableOn": "Netflix",
"price": 9.99
},
{
"id": 905,
"title": "TRAINSPOTTING STRANGERS",
"review": 3.9,
"reviewText": "For a while it seems it wants to be the franchise’s ‘Mission: Impossible.’ Instead, it’s the anti–‘Top Gun: Maverick’.My co-worker Ali has one of these. He says it looks towering.",
"availableOn": "Now TV",
"price": 13.99
},