Backends for frontends
- Date
 Michael Stone
Michael Stone
Here at Orbital, we’re interested in all things integration and backends-for-frontends (BFFs) fall squarely in that category. From one perspective, they’re simply a transformation and aggregation layer. Others would say they exist to tightly align with the requirements of the different frontends in your stack.
We prefer to see them as an API that’s customized for a single consumer rather than many consumers like typical APIs. It flips the concept of who an API is built for on its head.
This is the first of two posts with our take on BFFs. First we’ll take a look at the pattern itself, why they emerged and what the trade offs are. In our follow-up we’ll go through how Orbital acts as a BFF and why it’s an elegant solution (if we don’t say so ourselves)
How did they become a thing?
Historically, developers build APIs from the perspective of the backend system. They create models based on their own domain. Patterns like REST let them split entities into clean and well-structured endpoints. Which is all completely rational if you’re building one of those systems.
Enter UX designers who (rightly so) have very different ideas and are concerned with how to create an intuitive and pleasant interface. They care not if we’re serving User and Post data from two different systems and laugh in the face of the completely rational schema designs.
Backends-for-frontends is a pattern that emerged to resolve this tension. It allows us to cater for the different data fetching needs of web and mobile applications. However, the functionality and type of data are often similar across both mobile and desktop platforms. So, when developers started creating more complex mobile applications in the 2010s, it made sense to use the same backend systems as their desktop counterparts.
As the designs for desktop and mobile diverged, so did the requirements for the APIs serving them.
As the designs for desktop and mobile diverged, so did the requirements for the APIs serving them. The importance for optimizing for mobile meant fixing issues like over-fetching data on limited bandwidths. At the end of this path, it’s common to have similar data, all from the same domain, but very different API footprints.
Organizational structures accentuated these differences by using different teams to manage the frontend and backend systems. As the web and mobile teams were also split, backend teams became a bottleneck for implementing API requests.
Enter the BFF from stage-left. The savior of developers on both sides of this divide. Bringing gifts of freedom and autonomy for front end developers, and releasing backend developers from an onslaught of trivial requests to add fields. I can only assume that project managers celebrated in their own way too.
So what are they?
Assume we’re got a couple of frontend teams building separate desktop and mobile apps. Given the task of fetching data from our organization’s collection of services, let’s take a look at some of the options available to them.
Note: Although it’s more common to see this applied in microservices architectures, it’s equally relevant for monoliths. We’d still expect a monolith to split up their API into distinct endpoints over one or more domains.
DIY integration
The original method for this was something of a DIY approach. From each of our frontend applications, we’ll call out to each API and aggregate the data together. It’s basically everyone for themselves.
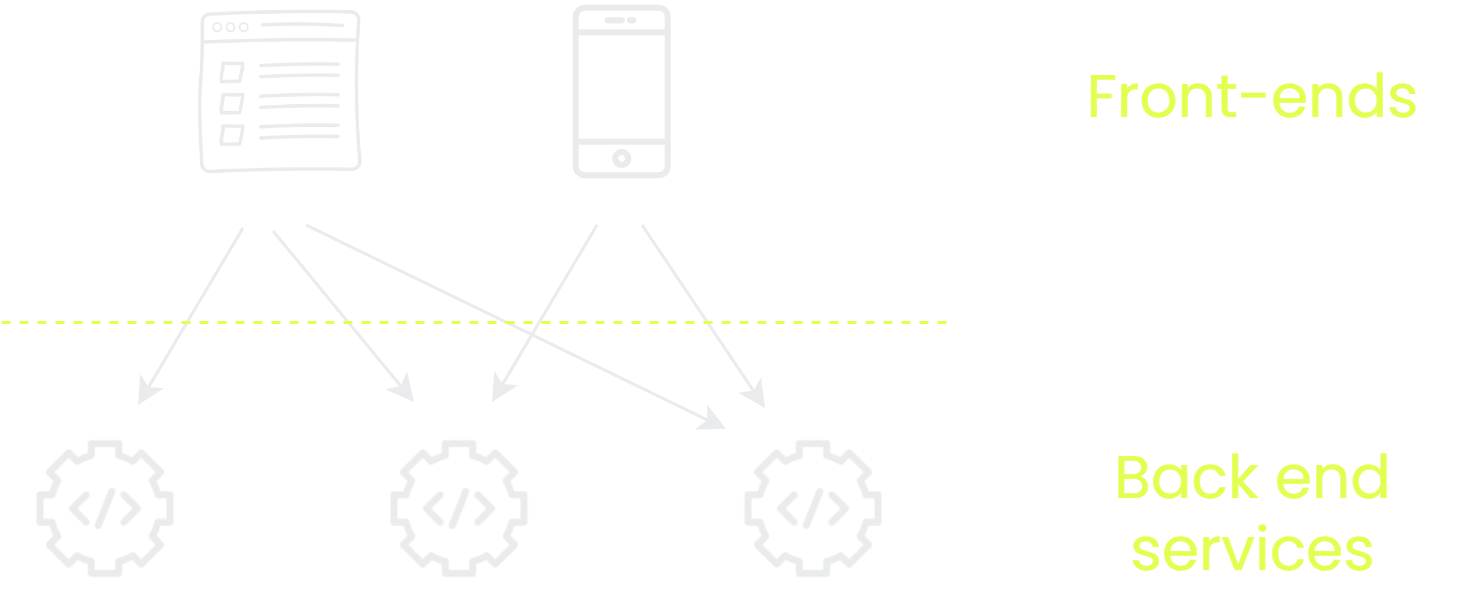
There’s nothing wrong with this, but we do import a bunch of complexity into our UI code. For each of the APIs we need to do things like:
- manage the connection config
- handle the success, failure or retry states
- import the individual domain models
And that’s assuming they’re all using a consistent protocol. It’s just as likely that one exposes a REST API with an OpenAPI spec, and another uses gRPC, or god forbid, SOAP.
General Purpose API
An improvement on this is to create a backend service that takes on some of this integration complexity. Each frontend is kinda doing the same thing if you squint a bit so maybe that makes sense.
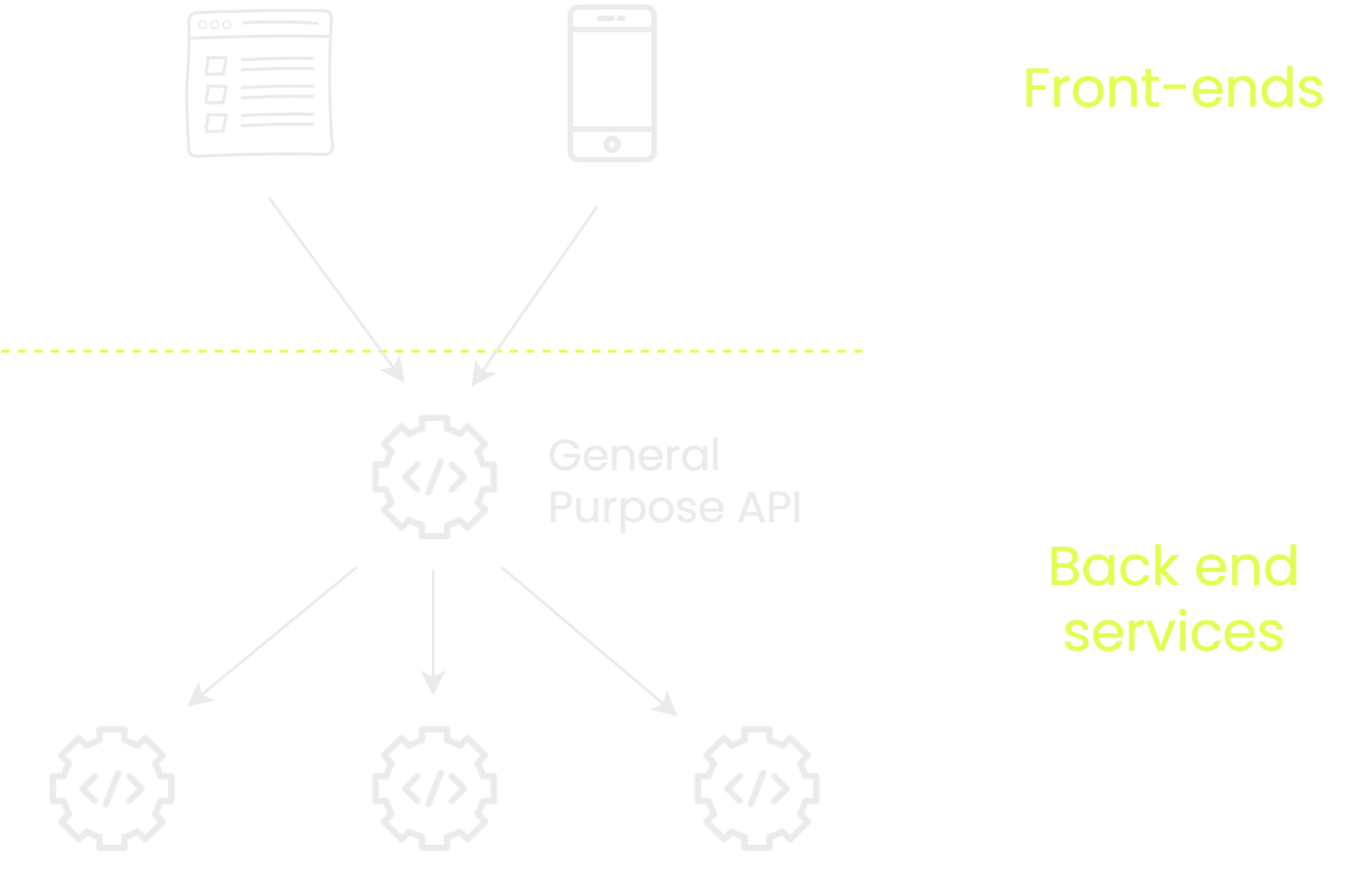
What you’d have then would be a bit more like a concierge. A high-end concierge, sure! They’ll be super polite, maybe even go above and beyond to get you what you want on occasion. Instead of having to know all the ins and outs of where to get your data from, you can rely on your concierge (general purpose API) to gather all the relevent data for you and put it in a nice little package. From the perspective of the front end apps, it’s much simpler to integrate with this one API with pre-aggregated data than to do that work themselves.
But they’re still serving any number of people, not just you. When the team building our general purpose backend gets approached by two different frontend teams, they’ve gotta balance both requests.
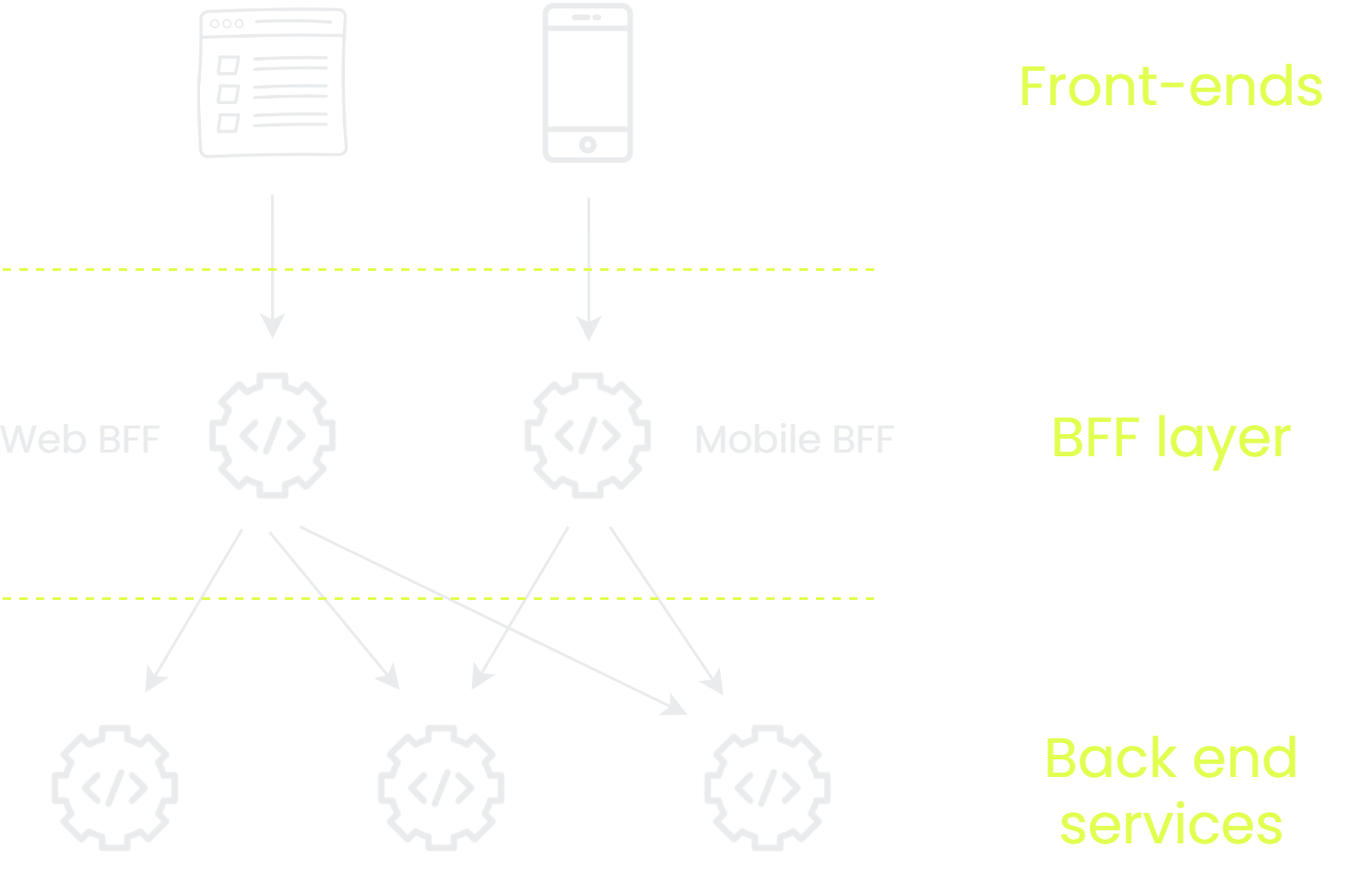
Backend-for-frontend
Backends for frontends are kind of like a personal butler for your frontend. They know how you like things done, are ready and willing to make any change you want, and sometimes even know you better than you know yourself (if Michael Caine is involved).
Backends for frontends are kind of like a personal butler for your frontend.
To meet the data fetching requirements of each frontend, we can create a distinct backend. That allow us to customize the API to serve exactly what we need and as a result improve our ability to solve over fetching or under fetching issues. If we want to trial GraphQL, we don’t have to convince a backend team to expose the same API in two different protocols, or have all our sibling frontends also switch over.
Since we’re not liaising with another team for changes, our whole change management cycle becomes easier too. Deploying a new feature that changes the API interface doesn’t need multi-team coordination. As such, the process to test, deploy and monitor the change to guard against an outage is much more contained. That flexibility is important where your deployments are via an App Store and somewhat out of your control.
What are the challenges?
By design a BFF is tightly coupled with our frontend systems. That leads to interesting questions about which team should own it, and what technology it should be built with. From a work division and scheduling perspective it makes sense to sit with the frontend team. They’re also going to be driving it’s implementation so that it works best with the frontend.
However, this leaves us with a awkward technical choice for our server side BFF. We either have to pick technologies to match the skills of frontend engineers, they need learn them, or we need to import them. Luckily there’s good options for web and Android frontend teams to at least use the same programming language. For Node.js there’s great frameworks like Express and Nest and on the JVM they’ve got options like Spring.
I’d argue though that the programming language used is only a component of the problem. There’s generally a wide gap in the bag of tricks required to work on a backend application compared to a frontend. A level of upskilling and extra complexity for the frontend team to deal with is inevitable in this autonomy trade-off.
A level of upskilling and extra complexity for the frontend team to deal with is inevitable in this autonomy trade-off.
We should also consider the raw time involved in building and deploying another service. With each frontend team now building and managing their own integration layer, there’s bound to be some duplication of code and effort as payment for the flexibility that we’re buying with this abstraction.
In terms of deployments, our tools have come a long long way and for many use cases it’s a simple click of the button. Once you leave the guardrails though, there’s often devops pain. As an intermittent, rather than full time devops engineer myself, scripting a cloud deployment and getting the infrastructure right can become a time-consuming task. Creating a separate BFF service buys a little more of that pain. That’s especially true if it’s the frontend team managing it as the infrastructure requirements will differ from those of the frontend code base.
Finally, although managing the coupling with the APIs of your downstream services is easier to manage in a BFF, the problem still exists. It’s just in a different place. When any of those services updates their API, our BFF needs to be updated too. For breaking changes, the mapping code we’ve written needs to be reviewed and modified, and run through the test-and-deploy cycle. That’s a win for isolating the effect of these changes and protecting our frontend code bases, but it’s still work that the frontend team needs to pick up.
What's next?
Next up I’ll be writing about how you can use Orbital for your Backend for Frontend without needing to create a new custom backend service. We’ll look at how Orbital helps with automatically adapting to changes in downstream services, and with supporting multiple versions of frontend app being used in the wild.
Other BFF material
If this hasn’t quenched your thirst for reading about BFFs, here’s a few other great articles.