Uniting similar data from multiple sources
- Date
 Michael Stone
Michael Stone
There’s plenty of legitimate cases where your company could have ended up with multiple services providing what is essentially the same type of data.
Possibly it’s as simple as a postcode resolution service, or it could be there’s a few Customer databases floating around. It’d be far too convenient for us for these sources to have stored exactly the same data, using exactly the same representation.
Even so, the content they contain almost certainly will have commonalities.
In the case of Customer data, you definitely wouldn’t be surprised to find a first name, last name and email address being represented in each system.
However, the way these fields are described may vary wildly, and you can’t help it if a developer long ago decided to label their last name property as frequently_inherited_name.
Regardless, the content of that field is equivalent to your last name, surname or family name fields which are present in the other Customer data sets.
Having systems that store and structure data in different ways is a Good Thing - we want our systems to be able to evolve independently, rather than conform to a rigid shared model. After all, you can’t force standardisation, without removing the ability for teams to evolve independently - and that’s not a tradeoff worth making.
What’s important is that there’s a common concept being represented, such as a Customer, an Order, or a Product.
Once our data scene has been set in this way, sooner or later someone in the business will realise that there’s some value to be gained by being able to query that spread out data in a consistent way. That’s the Chameleon pattern in action.
Where does this happen?
This is extremely common. Here’s a few examples that you might recognise:
- Your company may have grown up with independent divisions which have evolved separately and built their own versions of things
- Through success and good fortune, you’ve acquired a bunch of related littler companies, that each came with their own unique IT infrastructure.
- You’re using multiple providers for the same type of service (such as payments)
- You’re using multiple vendors for the same type of product (perhaps in your supply chain)
- You’ve started adopting microservices, and found that you’ve got duplicate services rearing their heads all over the place!
- It’s come time to deal with that dilapidated legacy system, and you’d sooner walk on hot ashes than do a big bang cutover
To handle these scenarios, typically we see a couple of different patterns implemented.
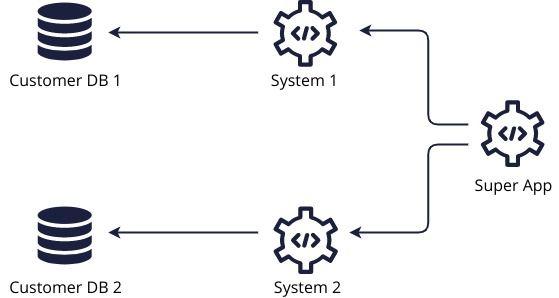
1. Consumers aggregate data themselves
The consuming system queries all providers separately and manually combines them.
If multiple systems need to consume the same data, each needs to build the same integrations with the source systems, and implement the same aggregation and reshaping code to convert the source data to something that’s useful to it.
This is great for developers who get paid per line of code.
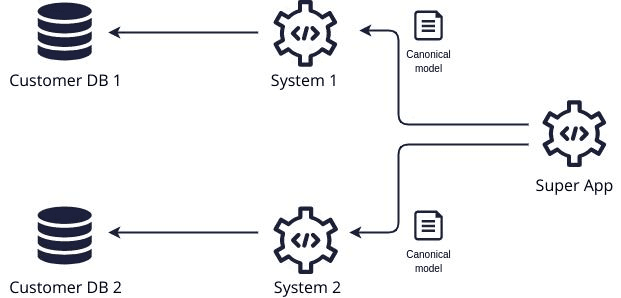
2. Our data providers expose canonical models
To save every consumer from the burden of integrating and reshaping the diverse data formats provided by source systems, you might think of forcing each provider to expose a canonical version of the data.
This helps our Super App developers to an extent, they still have to call out to every system, but at least the data is in the same format. The downside is that the data has to be in the same format! Both of our providers need to agree what a common definition of a customer model is. Cue the politics.
3. Our data is extracted to a separate store
An ETL pipeline is built to extract data from the providers and store it in a Data Lake or Data Warehouse in a normalized format
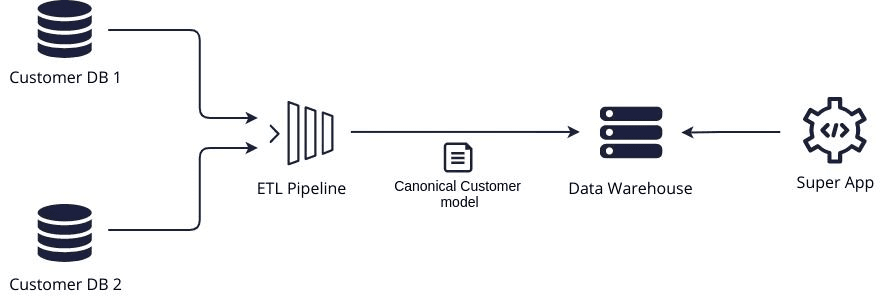
This solves the problem of each Super App that comes along having to solve the same problem of fetching and aggregating data from multiple sources, but it does bring with it some important restrictions.
The data is now coupled to the canonical model which has been enforced by the ETL pipeline and Data Warehouse. Getting functionality changes through to our Super App is now an IT project involving at least 3 teams (Source system, data pipeline and super app). This clearly makes the lead time of feature requests an immediate challenge.
Depending on your perspective of life as a data engineer, this is either fantastic or very frustrating. As the team building the pipelines and warehouse, you’re involved in all the action, but you’re not responsible for any end user functionality - and therefore the delivery pressure.
How Orbital does it
Orbital approaches this problem differently by providing a flexible data layer for consumers to query data. It automatically aggregates and reshapes the source data based on the needs of the consumer, saving you a huge amount of time typically spent on integrating with other systems and transforming data.
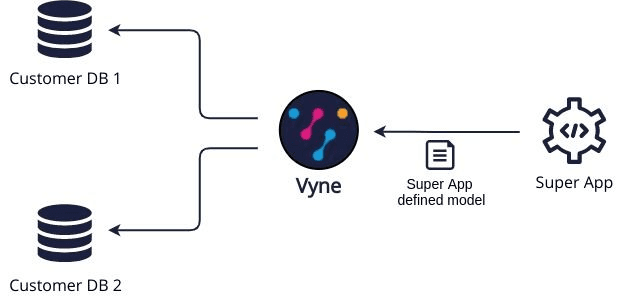
By using our open source data language, Taxi, we define a shared language of terms which can be used to describe the data provided by each individual system. This helps us to focus on the content of what systems are providing, rather than the format and structure of their data.
The result for our Super App is that by querying via Orbital, it’s not limited to the data which can be provided by the data pipeline layer. It also doesn’t have to worry about managing individual integrations with each provider. We get the best of both worlds!
As a bonus, when the providers inevitably change, Orbital adapts with them to ensure minimal impact to our Super App and other consumers. We don’t have to wait for negotiations about our canonical model, or for our data pipeline team to complete work to propagate changes. When our data providers change, we can immediately change with them. Dare I say it, but that sounds a little bit agile.