Why we created Taxi, and why we felt the need for Another Schema Language
- Date
 Marty Pitt
Marty Pitt
I’m often asked why we felt the need for another schema language - why not just use OpenAPI | SQL | Protobuf | GraphQL?
Inevitably, someone links that xkcd cartoon. Luckily, that cartoon is actually really funny, so I don’t mind re-reading over and over and over.

It seems the one standard the internet can agree on is to respond to discussions about schema languages with that cartoon.
However, it’s a fair question, and one that deserves a good answer. So, to summarize:
- Yes, Taxi is another schema language. It’s different.
- Yes, we felt there need for one more. It has different goals than the others, and addresses shortcomings we felt existed.
- Yes, there’s now one more way to do things… kinda (We don’t expect you to migrate from OpenAPI to Taxi.)
What is Taxi?
Taxi is a language for documenting data models and data sources (APIs, Event streams, Databases).
It’s designed for describing how data relates across an ecosystem of datasources (such as an enterprise), rather than a single API.
We do this so we can automate orchestration and interoperability between data sources, without writing glue code.
Where most schema languages describe a single data source (API, Event Stream, Db, Serverless function), Taxi is designed for describing how data relates across an ecosystem of datasources (such as an enterprise).
Taxi can partially describe:
- Databases - but you can’t replace DDL with Taxi.
- HTTP APIs - but you’ll probably keep using OpenAPI / gRPC - and that’s cool.
- Message queues, like Kafka and Rabbit - but you can’t replace Protobuf with Taxi.
For example, here’s a Taxi spec describing a database, a Kafka topic, and a REST API:
service FilmsDatabase {
table films : Film[]
}
model Film {
filmId : FilmId inherits String
}
service FilmEvents {
stream newReleases: Stream<NewReviewSubmittedEvent>
}
model NewReviewSubmittedEvent {
filmId : FilmId
reviewId : ReviewId inherits String
}
service ReviewsApi {
@HttpOperation(method = "GET", url = "https://reviews/{id}")
operation getReviews(id: FilmId): FilmReview[]
}
model FilmReview {
id: ReviewId
filmId: FilmId
score: ReviewScore inherits Int
}There’s enough metadata there for us to understand how everything hangs together - here’s a diagram of that spec:
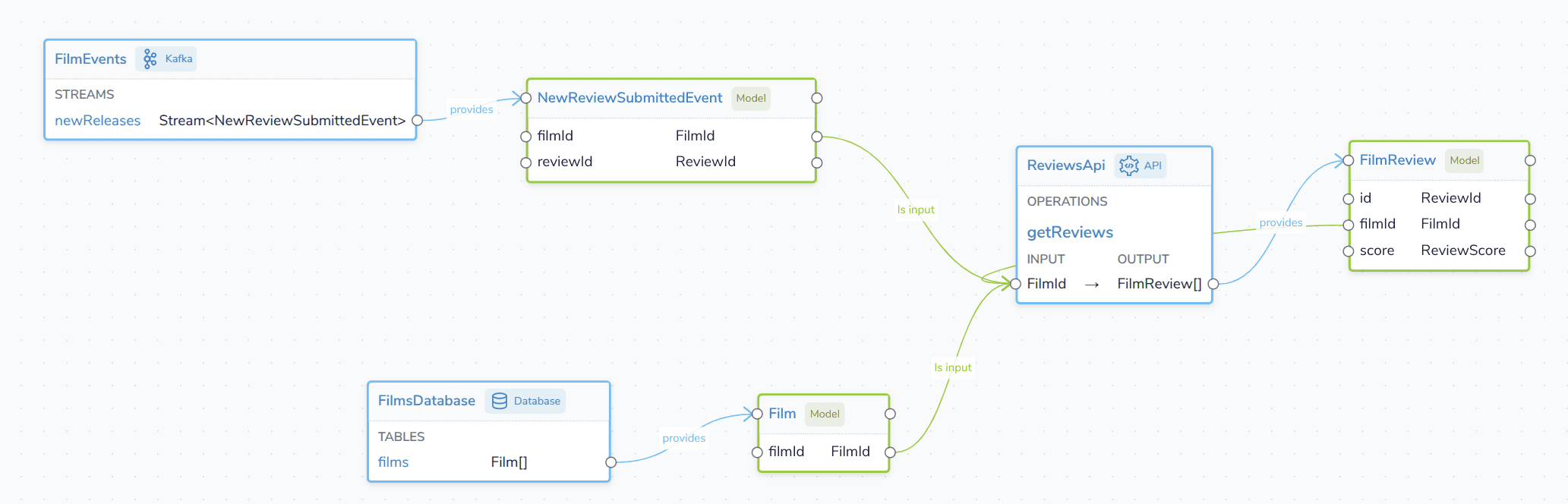
Taxi embeds within existing specs
In practice, Taxi actually breaks down into two separate activities:
- Defining a set of semantic scalar types, that describe a single field, which live in a Taxi project. These are designed for sharing.
- Embedding references to those types within existing API specs.
Our example above breaks down into a few simple types:
// A taxi project. Generally, this is committed into
// a Git repo somewhere.
type FilmId inherits String
type ReviewId inherits String
type ReviewScore inherits IntAnd some other specs:
openapi: 3.0.1
info:
title: ReviewsApi
version: 1.0.0
paths:
https://reviews/{id}:
get:
parameters:
- name: id
in: path
required: true
schema:
type: string
x-taxi-type:
name: FilmId # <-- Taxi metadata
responses:
"200":
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/FilmReview'
components:
schemas:
FilmReview:
type: object
properties:
id:
type: string
x-taxi-type:
name: ReviewId # <-- Taxi metadata
filmId:
type: string
x-taxi-type:
name: FilmId # <-- Taxi metadata
score:
type: integer
format: int32
x-taxi-type:
name: ReviewScore # <-- Taxi metadataWhy do this?
At Orbital, we’re on a mission to eradicate integration code.
Even though we were heavy users of OpenAPI, we found that when consuming APIs there’s a tonne of busywork in writing glue code stitching things together.
Often, we were composing multiple APIs together to achieve a single task. Each API required more glue code, and meant we were tightly coupling to that spec - meaning when the spec introduced breaking changes, our glue code had to be repaired.
That seemed silly. Even though we had all these specs that describe what APIs do, it still fell to engineers to work out which API to call, what data to pass for inputs, and write the glue code.
Even though we had all these specs that describe what APIs do, it still fell to engineers to work out which API to call, to track down inputs, and write the glue code.
We wanted to provide a way to let APIs describe themselves richly enough that software could work out how to orchestrate them together automatically. We also had some other goals:
- We shouldn’t be relying on field names - they’re a bad proxy for semantics, and teams should be free to chose names that make sense to their domain.
- We shouldn’t force teams building APIs to replace their existing specs with something new - we want to complement what’s already in place.
- We had to be technology-agnostic. Modern enterprises are heterogeneous, so we needed to work everywhere.
- Teams building APIs need to be able to change their APIs easily, without cascading change onto consumers.
Producer vs Consumer - Once vs Many times
Taxi shifts the obligation of describing how things stitch together from Consumers to Producers.
Traditionally, it falls to consumers to work out how to do this.
And, it’s an expensive question to answer… it involves tracking down API specs, reading docs, and building a mental model of how things hang together.

That sucks, because consumers are a-plenty, meaning that the “how does this relate to that” is answered over and over.
Instead, with Taxi, we shift the obligation of documenting how things relate to producers, by embedding metadata in their APIs.
This means work is done once - by the teams who understand the APIs the best - the ones building it.
What if teams put the wrong metadata?
Yeah, that’s a problem. If teams map fields together incorrectly, then the wrong APIs are stitched together.
But, that problem exists today - every time a new consumer stitches together some APIs, they’re performing the Field Mapping Foxtrot, and there’s a chance they’ll get it wrong.
So, by leaving it to consumers to map fields together, we’re actually facing this risk over and over.
In practice, the teams who are building the API have a much deeper understanding of how their data relates to the broader ecosystem, as they know their API best. And, whilst producers can’t map their APIs to all consumers, they can attach a piece of well-defined metadata that assigns a semantic contract we all agree on.
That being said, I think tooling can help more here than we do currently. Watch this space.
What is TaxiQL?
TaxiQL is part of the Taxi Spec - it’s a query language that lets consumers ask for data they want using the same semantic types that producers have embedded in their API specs.
find { Film( Title == 'Gladiator' ) } as {
title: FilmTitle
cast : {
actorName : FirstName + ' ' + LastName
twitter : TwitterHandle
}[]
rating: ReviewScore
reviews: ReviewText[]
}Taxi works just as well with request-response interfaces, as well as streaming data sources:
// Whenver a new film review is emitted, give me the data I want.
stream { FilmReviewSubmittedEvent } as {
title: FilmTitle
cast : {
actorName : FirstName + ' ' + LastName
twitter : TwitterHandle
}[]
rating: ReviewScore
reviews: ReviewText[]
}By using types in the consumer contract, and combining with the metadata in producers, there’s enough information to infer how everything hangs together, and to automate the integration.
TaxiQL vs GraphQL
Both Taxi and GraphQL share similar goals - providing a single entrypoint for composing multiple APIs together. GraphQL has been a strong inspiration in how we’ve designed Taxi.
However, there are key differences in their approach.
No global schema
GraphQL defines a single global schema that all consumers adhere to. Consumers can cherry-pick the fields they want, but the structure is fixed.
That global schema can create friction to change - if you need to refactor the schema, you either need to make backwards compatible changes, or consumers need to update.
Which is to say - evolving a shared structural contract is hard, and someone needs to take the hit - either the schema owner (through maintaining a backwards compatible change), or the consumers (by fixing what breaks when the schema changes).
This isn’t just a GraphQL issue - it’s true of any structural contract that is widely shared - they’re hard to change.
Consumer driven contracts
GraphQL has consumer-driven-contracts-lite. ie., consumers can cherry-pick the fields they want from the global schema. However, that’s it - structure, encoding, etc is fixed.
If you want to consume data in a different shape, you’ll need to map the data on the consumer side.
Those additional mapping layers are troublesome - each mapping layer you build is a tight coupling between contracts - ie., a thing that has to change when the upstream contract changes.
Instead, with Taxi, consumers define the data contract they want to consume in the request they send.
There is no single central schema - producer APIs are composed together on-the-fly to satisfy the consumer contract.
The types and query language provide enough flexibility that consumers can express the exact contract they require, and the middleware can understand how to assemble a response.
No resolvers
GraphQL uses resolvers to stitch together APIs - which is exactly the type of integration code we’re on a mission to eliminate.
As APIs change, resolvers need to be maintained and updated.
Generally, with Taxi you don’t need resolvers - the API specs are rich enough to automate the resolvers.
Technology-agnostic
GraphQL requires GraphQL everywhere, or shims to adapt to GraphQL.
Taxi (and taxiQL) is trying hard to keep the footprint low - Taxi will happily compose together a Kafka topic publishing Protobuf, with a gRPC service, some REST APIs, and a database.
What about implementations?
Taxi - the spec, compiler, and tooling ecosystem are all open source. Head over to Github and give it some stars.
The TaxiQL query server is currently part of Orbital - which we’re working to open source this summer. In the meantime, you can take it for a spin following our getting started guide.
Summary
So, here’s the key takeaways:
Taxi exists to describe how data and data sources relate to one another, and to automate interoperability.
OpenAPI, SQL, Protobuf, etc., all do a great job of describing a single data source. By adding additional metadata into those APIs, we have enough information to automate integration between services, without writing (or maintaining) glue code.
TaxiQL is a way to use Taxi types to ask for data, and for consumers to remain decoupled from producer schemas, so as things change, there’s no glue code to maintain.
XKCD is the one true standard, which is how it was always meant to be.