How Orbital Works: Semantic layers and integration
- Date
 Marty Pitt
Marty Pitt
Introduction
In this post, I’ll unpack how Orbital uses a Semantic Layer to automate integration.
If you’ve never heard of Orbital, or semantic integration before - 👋 Welcome! Orbital is a open core data and integration platform on a mission to eliminate integration code.
Our goal is to connect APIs, events and databases on demand, and have those integrations adapt automatically as systems change.
I’ve written in the past about why we created Taxi, and the ideas behind semantic metadata. But, for the impatient - here’s a quick primer:
- Modern companies run hundreds of APIs, event streams, databases, and CSVs.
- Teams wire these together with point-to-point glue code.
- Those connections break every time something changes.
- Orbital replaces glue code with semantics: systems describe their data through enriched API specs (OpenAPI, Protobuf, Avro, SOAP, etc.).
- Integrations are then expressed semantically — not imperatively.
- When systems evolve, Orbital reads the new specs and updates the integrations automatically.
Semantics and Taxi
Orbital is powered by Taxi - a language we created for modelling data semantically.
It lets you add additional metadata to API specs, beyond field names. It let’s use formally define concepts, and then tag those concepts into our API specs.
For example, let’s imagine we’re modelling a simple Film domain. We might define some concepts:
namespace acme.films
type Title inherits String
type FilmId inherits Int
type ReviewScore inherits Int
type DurationInMinutes inherits IntWe can embed these concepts inside an OpenAPI spec (most standard API specs are supported) for a service that returns information about film reviews:
Note
We'll show an example here (scroll down to see the Taxi bits), but for the rest of post, we're going to show examples in Taxi, for brevity. These same approaches work with OpenAPI, Avro, Protobuf, and many others.
We've included the same snippet in pure Taxi, so you can see compare the difference.
# An extract of the ShoppingCartApi OpenAPI spec:
openapi: 3.0.3
info:
title: Reviews API
version: 1.0.0
paths:
/reviews/{filmId}:
get:
summary: Get reviews for a film
operationId: getReviews
parameters:
- name: filmId
in: path
required: true
schema:
$ref: '#/components/schemas/FilmId'
description: ID of the film
responses:
'200':
description: A list of reviews for the specified film
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Review'
components:
schemas:
Review:
type: object
required:
- film
- score
x-taxi-type:
name: acme.films.Review ## <--- That's semantic metadata (Taxi)
properties:
film:
type: integer
x-taxi-type:
name: acme.films.FilmId ## <--- That's semantic metadata (Taxi)
score:
type: integer
x-taxi-type:
name: acme.films.ReviewScore ## <--- That's semantic metadata (Taxi)
There’s not much to see there - and that’s kinda the point…
Semantic metadata is a thin layer of additional information you add to your existing API specs
TaxiQL - Semantic query language
TaxiQL is the query language of Taxi, and the way that we ask for data from our semantic layer.
It’s strongly typed, declarative, and driven entirely by semantics.
Here’s an example of a Taxi query to fetch data from the Reviews API:
This is interactive
Fetching data from a REST API
Now, this on it’s own isn’t particularly exciting, so lets add some other data sources.
Linking data between sources
Fetching data from a single API is cool ‘n all, but it’s not really the point of a semantic layer.
Things start to get interesting when we add other data sources. Let’s add a database containing film data.
enum FilmRating {
G,
PG,
R18
}
model Film {
id : FilmId
title : Title
duration : DurationInMinutes
censorRating: FilmRating
}
service FilmsDb {
table films : Film[]
}Now, our semantic layer understands how data links across two sources:

This time, we can run a query asking for data from both sources:
Linking data from a database and an API
What just happened?
This time, when the query ran, the query engine worked out that to return the requested data, it’d need to link data across multiple sources.
Here’s the query plan for that query:
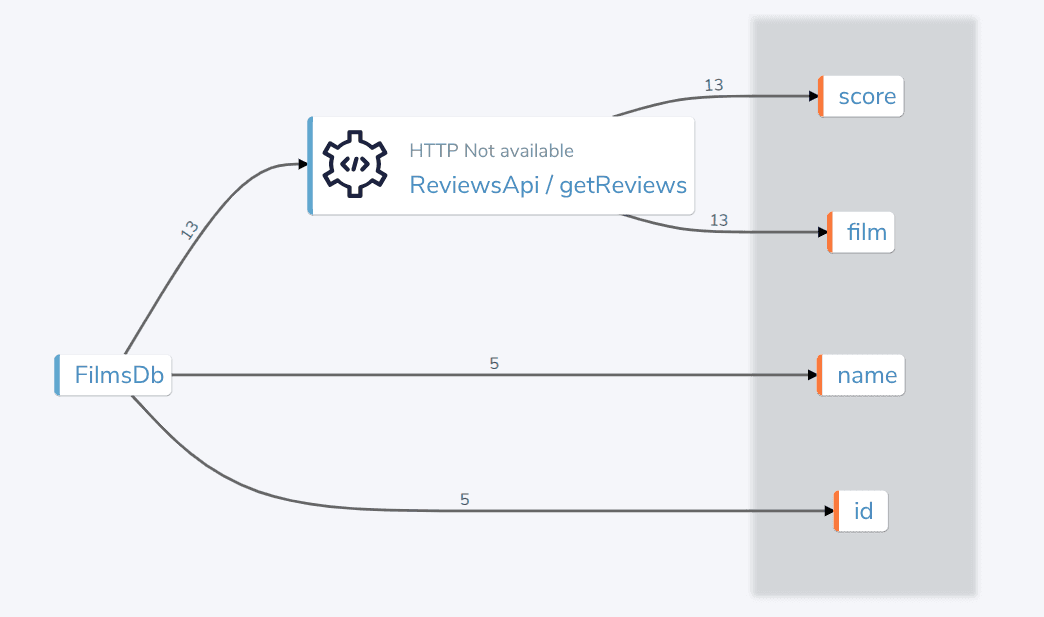
So, we’re fetching data from a database, then enriching it with a series of Rest API calls.
Our query didn’t need to specify how to link that data, the query engine worked it out by using the Semantic layer.
Consumer data contracts
You might’ve noticed in the above example that the consumer defined a Data Contract of the shape of data it wanted to retrieve. Let’s look again:
find { Film[] } as {
id: FilmId
name : Title
reviews: Review[]
}[]
By letting consumers define their own data contract - including field names, response shapes, and composing data sources together, it keeps our consumers and producers entirely decoupled.
Declarative, and adaptive
What’s nice about this approach is that the queries are entirely declarative - we don’t specify which services to call, tables to query, or which fields to map.
That’s particularly powerful, because as things change, consumers remain unaffected.
Our first example was pretty simple - the Id from our database was fed straight to our Reviews API.
However, it’s common in an enterprise for entities to have different Id schemes. Typically, this gets resolved via some kind of lookup API.
So, let’s introduce that complexity:

We’ll update our semantic layer. Typically, this would happen by changing the OpenAPI specs, but we’re going to just show the Taxi, to keep things short’n’sweet.
model FilmIdLookupResponse {
filmdId: FilmId
reviewsId: FilmReviewId
}
service FilmIdResolverApi {
operation lookupIds(FilmId):FilmIdLookupResponse
}
service ReviewsApi {
// Note the getReviews API no longer accepts a FilmId.
// It has a different type of input - a FilmReviewId
@HttpOperation(method = "GET", url = "/reviews/{filmId}")
operation getReviews(@PathVariable("filmId") filmId:FilmReviewId):Review[](...)
}Normally, this kind of change would be a breaking change - our consumers would need to call the additional API. Or, if we were using graphQL, we’d need to update our resolvers.
However, because Taxi and TaxiQL are semantic, rather than imperative, for our consumer, nothing changes.
Here’s that same query, again - try clicking run, or open it in the playground to get a better sense:
Database and enriched data via two Lookup APIs
So, even though for the consumer the query hasn’t changed, internally the query plan now looks like this:
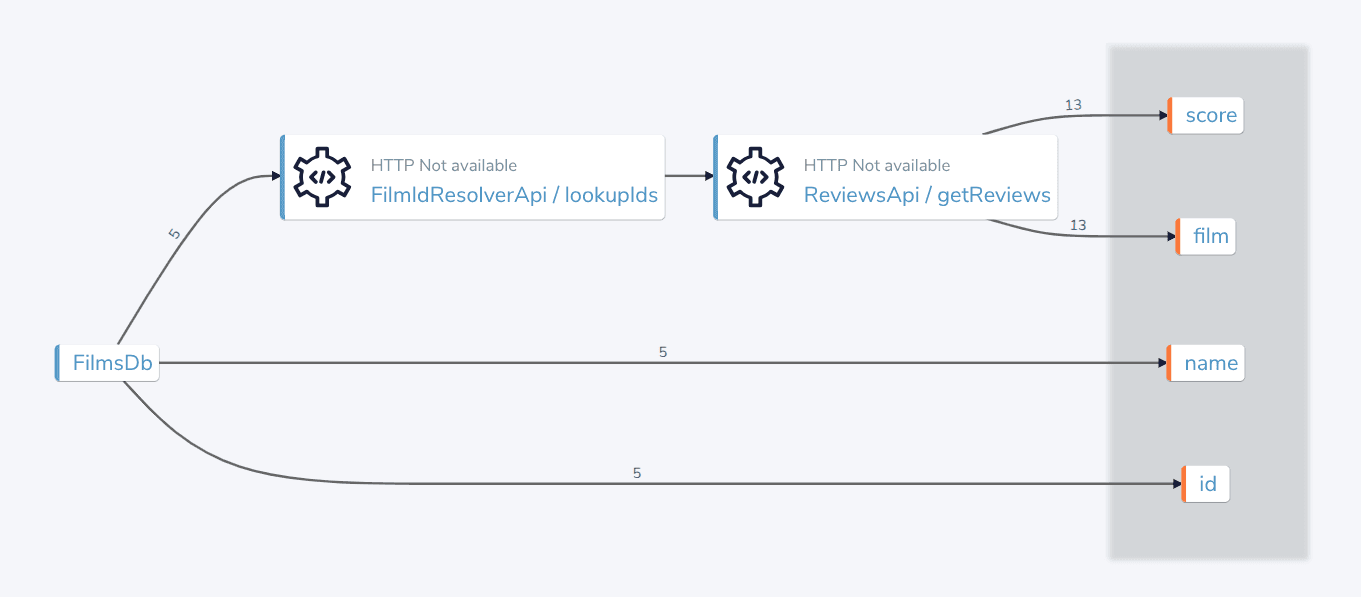
Notice we’re adding an additional call to handle resolving the id’s.
How does this work?
Internally, all of the semantics get transformed into a huge graph, that our query engine can traverse at query-time:

The query engine breaks down the TaxiQL query into an AST, and then runs this graph resolution for every field requested by the query - working out how to fetch data by traversing the graph, and calling APIs (or databases, or Kafka topics, or S3 buckets, etc. etc.)
The query engine applies optimisations, like batching requests, and caching responses to ensure that everything stays fast.
This means we can do away with things like Resolvers, or point-to-point integration logic, eliminating the parts of our code that break as teams update and evolve their APIs.
Semantic layers for AI's
As you may have noticed, there’s very little code - or contextual information - involved in all this. This makes it ideally suited for LLM’s and AI copilot / code agents, as the context window is significantly smaller.
The LLM doesn’t need to know about all the different APIs or how to stitch everything together. It simply has to translate user requirements from plain english to a semantic query. And, it turns out that LLM’s are really really good at rephrasing text into a constrained set of terms, using a simple syntax.
eg:
Find me a list of films. Include their title, and a list of reviews
Becomes:
find { Film[] } as {
id: FilmId
name : Title
reviews: Review[]
}[]If you’re interested in seeing this in action - check out this demo of Luna - our AI Copilot for integration: