Benchmarking LLM Accuracy in Real-World API Orchestration
- Date
 Marty Pitt
Marty Pitt
Introduction
AI agents are becoming a core part of enterprise integration - not just for pre-built flows like ETL and API aggregation, but for ad-hoc, on-demand orchestration inside real-time agent workflows.
As adoption accelerates, a key question is whether LLMs can reliably navigate the complexity of real-world API estates.
So we set out to answer:
How well can LLMs plan workflows which orchestrate multiple APIs together, under real-world conditions?
We recently completed a detailed study into exactly this - measuring LLM accuracy when planning API orchestration tasks under increasingly realistic conditions.
We gave the agents a task (in the form of an “email from my boss”), and an (ever increasing) collection of OpenAPI specs, and asked them to design a solution.
We then scored them against scoring criteria, running each test 30 times, and averaged the results.
If you’re in a hurry, here’s a link to the results.
Key findings
We found four key facts:
- Planning accuracy falls to unusable levels somewhere between 60 and 300 endpoints
- Adding even minimal semantic metadata improves planning accuracy
- A declarative query language improved planning accuracy by between 73% to 142%
- Using Taxi for APIs (instead of OpenAPI) reduced token usage by 80%
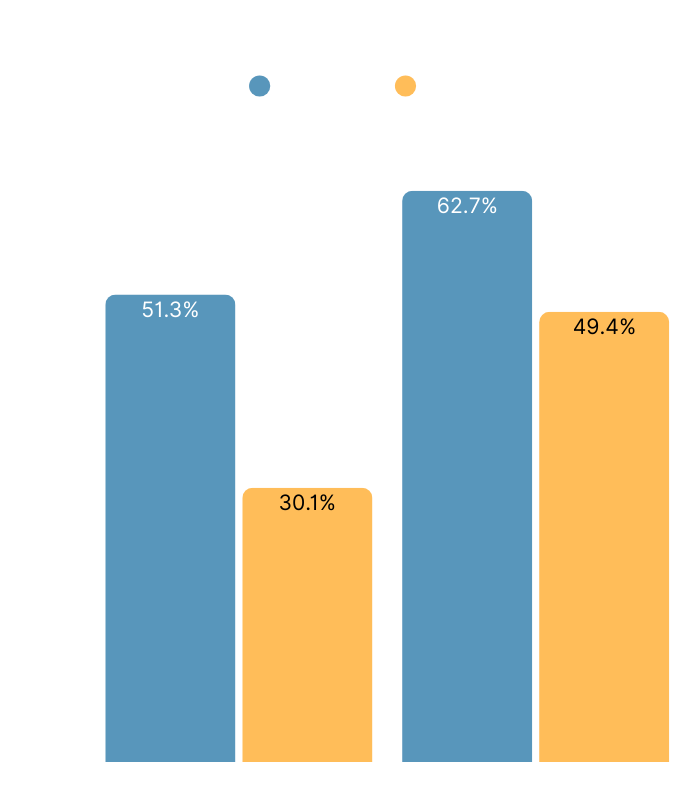
Planning accuracy falls to unusable levels somewhere between 60 and 300 endpoints
Planning accuracy (more on how we measured this below) fell to ~30% and ~49% once we increased the population of endpoints to 300.
Interestingly, the degradation didn’t continue at 600 endpoints. We were surprised by this and don’t have a clear answer as to why.
Note: An “endpoint” is a Path and a Verb (eg: GET /customers/123)
| # of endpoints | Sonnet 4.5 | ChatGPT 5.1 |
|---|---|---|
| 60 endpoints | 51.3% | 62.7% |
| 300 endpoints | 30.1% | 49.4% |
| 600 endpoints | 30.9% | 46.4% |
Adding even minimal semantic metadata improves planning accuracy
- We added semantic metadata to the OpenAPI specs on fields and input parameters.
- We updated our prompts to “consider semantic metadata (expressed via OpenAPI
x-taxi-typeannotations), which explicitly describe the semantic meaning of data contained within each field.” - We didn’t provide any additional information about “Taxi”, ”
x-taxi-type” or “Semantic Metadata” beyond what’s already present in standard base models
The impact was a meaningful increase in accuracy compared to baseline:
| Sonnet 4.5 | ChatGPT 5.1 | |
|---|---|---|
| 600 endpoints with plain OpenAPI | 30.9% | 46.1% |
| 600 endpoints with OpenAPI using Taxi annotations | 46.4% | 58.8% |
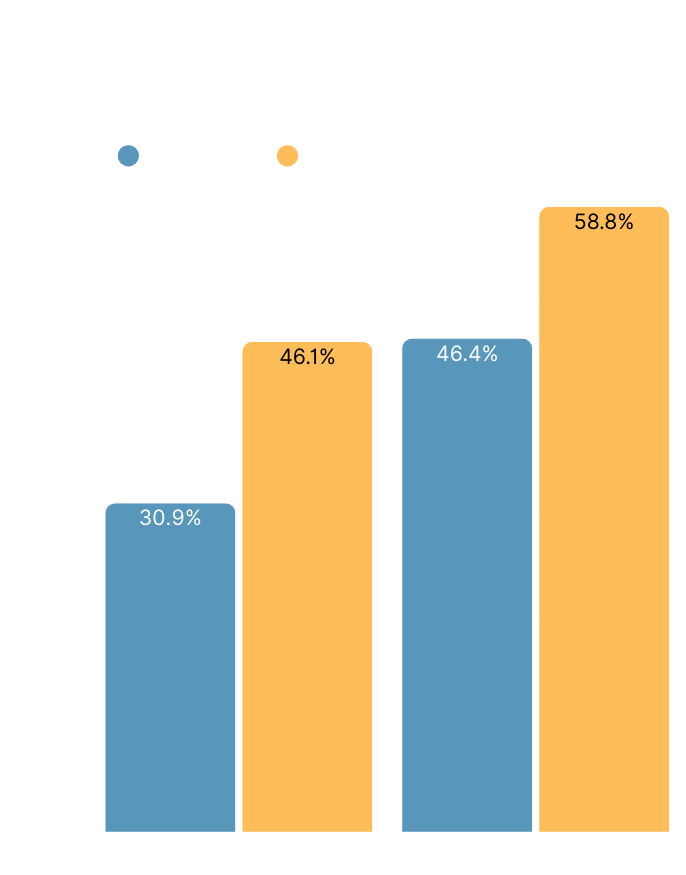
Importantly, this improvement came purely from base model knowledge of semantic metadata - we didn’t provide specialized prompts, examples, or training about how to use these annotations.
Example of semantic metadata
We added x-taxi-type annotations to the OpenAPI specs. To reiterate - we didn’t tell the LLMs anything more about what this was. In practice, both models appeared to be familiar
with Taxi and TaxiQL from their training data.
/quotes/{symbol}:
get:
summary: Get single quote
operationId: getQuote
parameters:
- name: symbol
in: path
required: true
schema:
type: string
x-taxi-type: com.bank.trading.Ticker
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/Quote'
And to response schemas:
components:
schemas:
Quote:
type: object
properties:
symbol:
type: string
x-taxi-type: com.bank.trading.Ticker
bid:
type: number
x-taxi-type: com.bank.trading.BidPrice
ask:
type: number
x-taxi-type: com.bank.trading.AskPrice
Adopting a declarative query language improves LLM planning accuracy by between 73% - 142%
We asked the agents to express data requirements using TaxiQL queries.
The result was a significant improvement in planning accuracy.
| Sonnet 4.5 | ChatGPT 5.1 | |
|---|---|---|
| 600 endpoints with plain OpenAPI | 30.9% | 46.1% |
| 600 endpoints with OpenAPI using Taxi + TaxiQL | 74.7% | 85.5% |
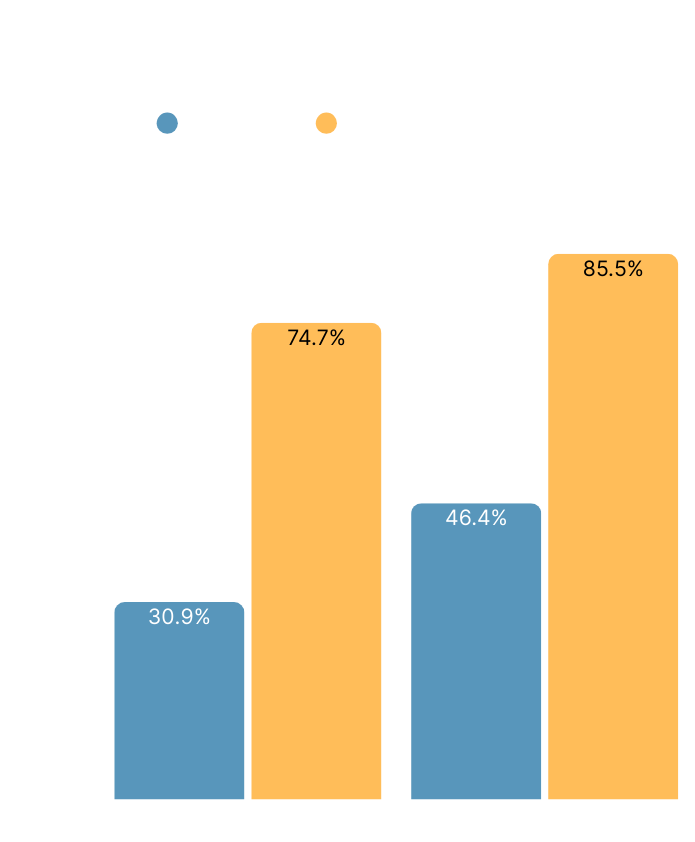
There’s some important caveats here:
- For this test run, we provided Taxi schemas, not OpenAPI.
- Critically, this reduced token usage by 80%, which meant much smaller context windows.
- LLMs were told to “outline the API calls as TaxiQL queries”
- We didn’t provide specific information about TaxiQL to the LLMs beyond what’s already in their base training
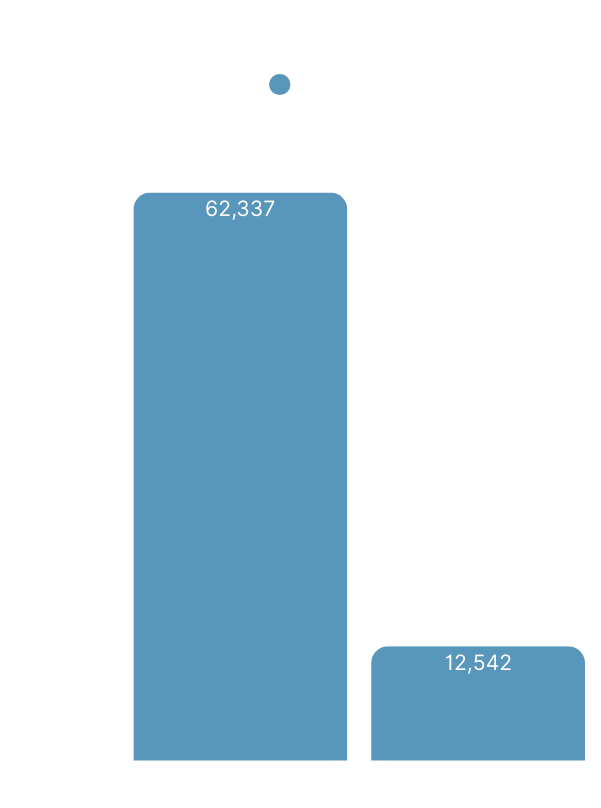
Using Taxi for APIs (instead of OpenAPI) reduced token usage by 80%
In the final tests (TaxiQL focussed) we sent API specs to LLMs in Taxi, rather than OpenAPI.
This dramatically reduced the consumed tokens (and therefore token size). As teams become sensitive to token spend, this is a quick win for budgets.
| Tokens consumed | |
|---|---|
| OpenAPI | 62,337 |
| Taxi | 12,542 |
For reference, here’s the same example from above, expressed in Taxi:
service QuotesApi {
@HttpOperation(method = "GET", path = "/quotes/{symbol}")
operation getQuote(symbol:Ticker):Quote
}
model Quote {
ticker: com.bank.trading.Ticker
bid: com.bank.trading.BidPrice
ask: com.bank.trading.AskPrice
}However, because we deferred orchestration to TaxiQL, the LLM doesn’t actually need to know about the service definitions, only the models and types, so the ACTUAL Taxi schemas ended up looking more like this:
model Quote {
ticker: com.bank.trading.Ticker
bid: com.bank.trading.BidPrice
ask: com.bank.trading.AskPrice
}(That’s 36 tokens vs 177 in the OpenAPI definition)
Scoring
What we measured - and why
We did this research to ask the question:
How good are LLMs at building an orchestration plan that spans multiple APIs?
More specifically - we wanted to ask three questions:
- How well do LLMs perform at API orchestration when facing real-world complexity (hundreds of endpoints)?
- Does adding semantic metadata improve their accuracy?
- Does the adoption of a declarative orchestration language (specifically TaxiQL) make a difference?
Disclosures
It’s important to be transparent about motivations - we did this research specifically because we’re investing in building in this area, and want to be sure that we’re both:
- addressing a problem that actually exists, and
- proposing a solution that works
However, we took care to test in a balanced way.
We didn’t give specialized training or prompting for the alternative approaches we were testing (which were adding a semantic layer, and using a declarative orchestration language — specifically TaxiQL).
Independently of the main research, we also tested how well the LLMs could produce real compiling TaxiQL queries. For this we did use specialized prompts (and we’re continuing to iterate them), but we’ve called these out separately in the research results.
How we measured
The agents were measured against 4 criteria:
- API Flow - The agents had to pick the correct 5 endpoints (path and verb), and sequence them in the correct order
- Correct Identifier - Multiple ID schemes were used. The agents had to recognize this, and call an API endpoint to swap IDs, passing in and reading out the correct fields
- Business logic - Agents needed to describe (but not implement) how data from API responses would be used to implement business logic checks, or to pass to the next API call
- Robustness - Data is messy - nulls and partial records exist — agents needed to describe how they’d handle this
Importantly:
- Agents only had to build an accurate plan. If they produced code, they weren’t penalized if the code didn’t compile.
To score:
- A scoring sheet defined the key elements agents needed to articulate
- We used multiple LLMs as judges in a multi-stage review process:
- Two separate LLMs scored the output against the scoring sheet (GPT-5.1 and Gemini-2.5 Pro)
- Both scoring results were sent back to an LLM to critique and refine the scores (Gemini-2.5-Pro)
- The first LLM reviewed critiques and had the opportunity to adjust its scores (GPT-5.1)
Each scenario was run and scored 30 times, and the scores were averaged
Summary
Our research shows that AI agents need a semantic layer to operate reliably in enterprise environments.
Without it, accuracy degrades to unusable levels as API complexity grows - exactly the conditions agents will face in production.
The encouraging result is that even minimal semantic metadata improves outcomes, and moving orchestration into a declarative layer (TaxiQL) improved planning accuracy substantially while reducing token consumption.
Both Taxi and TaxiQL are open source, making this approach accessible to any organization. Taxi is designed to be interoperable with existing schema languages, so you can start adding semantic metadata to your OpenAPI, Avro, SOAP, or Protobuf specs now - without retooling.
If you’d like to discuss applying this approach in your environment, join us on Slack or reach out by Email. Or you can simply try Orbital now.